The Design of a Practical System For Fault-Tolerant Virtual Machines #
Paper download: here
Abstract #
We have implemented a commercial enterprise-grade system for providing fault-tolerant virtual machines, based on the approach of replicating the execution of a primary virtual machine (VM) via a backup virtual machine on another server.
An easy-to-use, commercial system that automatically restores redundancy after failure requires many additional components beyond replicated VM execution. We have designed and implemented these extra components and addressed many practical issues encountered in supporting VMs running enterprise applications.
1. Introduction #
A common approach to implementing fault-tolerant servers is the primary/backup approach, where a backup server is always available to take over if the primary server fails.
One way of replicating the state on the backup server is to ship changes to all state of the primary, including CPU, memory, and I/O devices, to the backup nearly continuously. However, the bandwidth can be very large.
A different method for replicating servers that can use much less bandwidth is sometimes referred to as the state-machine approach. The idea is to model the servers as deterministic state machines that are kept in sync by starting them from the same initial state and ensuring that they receive the same input requests in the same order. Since most servers or services have some operations that are not deterministic, extra coordination must be used to ensure that a primary and backup are kept in sync.
Implementing coordination to ensure deterministic execution of physical servers is difficult, particularly as processor frequencies increase. In contrast, a virtual machine (VM) running on top of a hypervisor is an excellent platform for implementing the state-machine approach.
VMs have some non-deterministic operation (e.g. reading a time-of-day clock or delivery of an interrupt), and so extra information must be sent to the backup to ensure that it is kept in sync. Since the hypervisor has full control over the execution of a VM, including delivery of all inputs, the hypervisor is able to capture all the necessary information about non-deterministic operations on the primary VM and to replay these operations correctly on the backup VM.
We have implemented fault-tolerant VMs using the primary/backup approach on the VMware vSphere 4.0 platform. The base technology is known as deterministic replay. VMware vSphere Fault Tolerance (FT) is based on deterministic replay, but adds in the necessary extra protocols and functionality to build a complete fault-tolerant system.
At this time, the production versions of both deterministic replay and VMware FT support only uni-processor VMs. Recording and replaying the execution of a multi-processor VM is still work in process, with significant performance issues because nearly every access to shared memory can be a non-deterministic operation.
We only attempt to deal with fail-stop failures, which are server failures that can be detected before the failing server causes an incorrect externally visible action.
2. Basic FT Design #
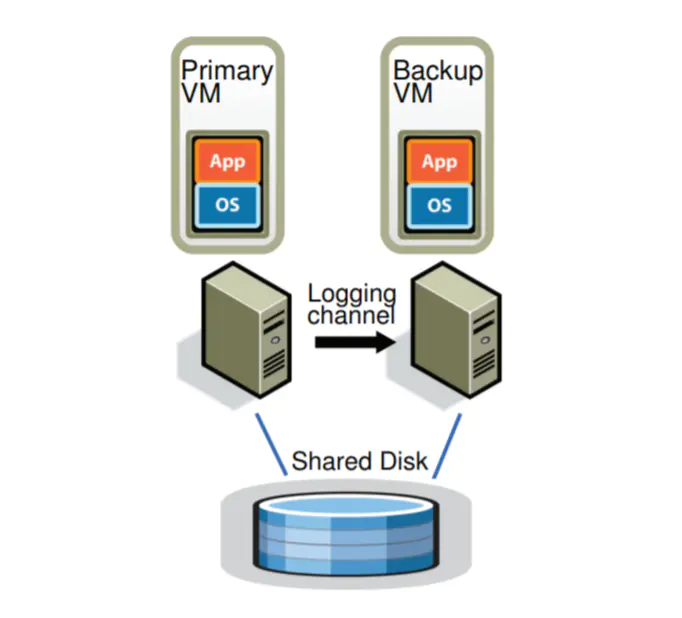
The two VMs are in virtual lock-step. The virtual disks for the VMs are on shared storage. Only the primary VM advertises its presence on the network, so all network inputs come to the primary VM. Similarly, all other inputs (such as keyboard and mouse) go only to the primary VM.
All input that the primary VM receives is sent to the backup VM via a network connection known as the logging channel. For server workloads, the dominant input traffic is network and disk. Additional information, as discussed below in Section 2.1, is transmitted as necessary to ensure that the backup VM executes non-deterministic operations in the same way as the primary VM.
The primary and backup VM follow a specific protocol, including explicit acknowledgments by the the backup VM, in order to ensure that no data is lost if the primary fails.
To detect if a primary or backup VM has failed, our system uses a combination of heart-beating between the relevant servers and monitoring of the traffic on the logging channel. In addition, we must ensure that only one of the primary or backup VM takes over execution.
2.1 Deterministic Replay Implementation #
As we have mentioned, replicating server (or VM) execution can be modeled as the replication of a deterministic state machine.
Non-deterministic events (such as virtual interrupts) and non-deterministic operations (such as reading the clock cycle counter of the processor) also affect the VM’s state. This presents three challenges for replicating execution of any VM running any operating system and workload:
- correctly capturing all the input and non-determinism necessary to ensure deterministic execution of a backup virtual machine.
- correctly applying the inputs and non-determinism to the backup virtual machine.
- doing so in a manner that doesn’t degrade performance.
In addition, capturing the undefined side effects in x86 microprocessors and replaying them to produce the same state presents an additional challenge.
VMware deterministic replay provides exactly this functionality for x86 virtual machines on the VMware vSphere platform. Deterministic replay records the inputs of a VM and all possible non-determinism associated with the VM execution in a stream of log entries written to a log file.
For non-deterministic operations, sufficient information is logged to allow the operation to be reproduced with the same state change and output. For non-deterministic events, the exact instruction at which the event occurred is also recorded. During replay, the event is delivered at the same point in the instruction stream.
2.2 FT Protocol #
We must augment the logging entries with a strict FT protocol on the logging channel in order to ensure that we achieve fault tolerance. Our fundamental requirement is following:
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world.
The Output Requirement can be ensured by delaying any external output (typically a network packet) until the backup VM has received all information that will allow it to replay execution at least to the point of that output operation. One necessary condition is that the backup VM must have received all log entries generated prior to the output operation. However, suppose a failure were to happen immediately after the primary executed the output operation. The backup VM must know that it must keep replaying up to the point of the output operation and only “go live” at that point. If the backup were to go live at the point of the last log entry before the output operation, some non-deterministic event (e.g. timer interrupt delivered to the VM) might change its execution path before it executed the output operation.
Given the above constraints, the easiest way to enforce the Output Requirement is to create a special log entry at each output operation. Then the Output Requirement may be enforced by this specific rule:
Output Rule: the primary VM may not send an output to the external world until the backup VM has received and acknowledged the log entry associated with the operation producing the output.
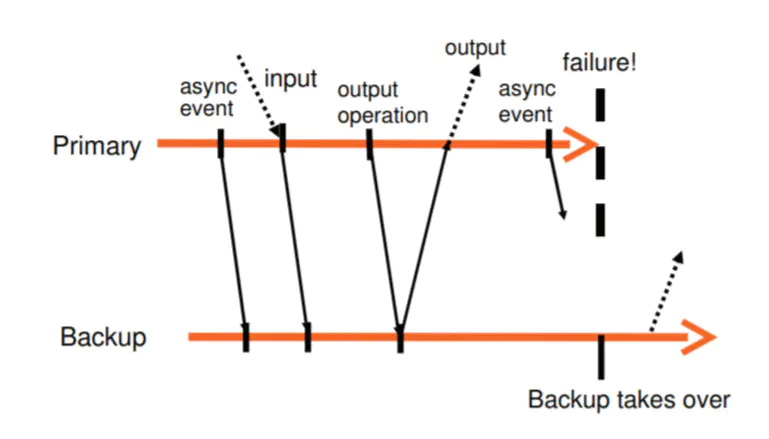
Note that the Output Rule does not say anything about stopping the execution of the primary VM. We need only delay the sending of the output, but the VM itself can continue execution.
We cannot guarantee that all outputs are produced exactly once in a failover situation. Without the use of transactions with two-phase commit when the primary intends to send an output, there is no way that the backup can determine if a primary crashed immediately before or after sending its last output.
2.3 Detecting and Responding to Failure #
The primary and backup VMs must respond quickly if the other VM appears to have failed.
-
If the backup VM fails, the primary VM will go live – that is, leave recording mode (and hence stop sending entries on the logging channel) and start executing normally.
-
If the primary VM fails, the backup VM should similarly go live – the backup VM must continue replaying its execution from the log entries until it has consumed the last log entry, then it will stop replaying mode and start executing as a normal VM. In essence, the backup VM has been promoted to the primary VM. VMware FT automatically advertises the MAC address of the new primary VM on the network, so that physical network switches will know on what server the new primary VM is located. In addition, the newly promoted primary VM may need to reissue some disk IOs (as described in Section 3.4)
VMware FT uses UDP heartbeating between servers that are running fault-tolerant VMs to detect when a server may have crashed. In addition, VMware FT monitors the logging traffic that is sent from the primary to the backup VM and the acknowledgments sent from the backup VM to the primary VM.
However, any such failure detection method is susceptible to a split-brain problem. To avoid split-brain problems, we make use of the shared storage that stores the virtual disks of the VM. When either a primary or backup VM wants to go live, it executes an atomic test-and-set operation on the shared storage.
One final aspect of the design is that once a failure has occurred and one of the VMs has gone live, VMware FT automatically restores redundancy by starting a new backup VM on another host.
3. Practical Implementation of FT #
To create a usable, robust and automatic system, there are many other components that must be designed and implemented.
3.1 Starting and Restarting FT VMs #
One of the biggest additional components that must be designed is the mechanism for starting a backup VM in the same state as a primary VM. This mechanism will also be used when re-starting a backup VM after a failure has occurred.
For VMware FT, we adapted the existing VMotion functionality of VMware vSphere. We created a modified form of VMotion that creates an exact running copy of a VM on a remote server, but without destroying the VM on the local server. That is, our modified FT VMotion clones a VM to a remote host rather than migrating it. The FT VMotion also sets up a logging channel, and causes the source VM to enter logging mode as the primary, and the destination VM to enter replay mode as the new backup.
Another aspect of starting a backup VM is choosing a server on which to run it. VMware vSphere implements a clustering service that maintains management and resource information. The clustering service determines the best server on which to run the backup VM based on resource usage and other constraints and invokes an FT VMotion to create the new backup VM.
3.2 Managing the Logging Channel #
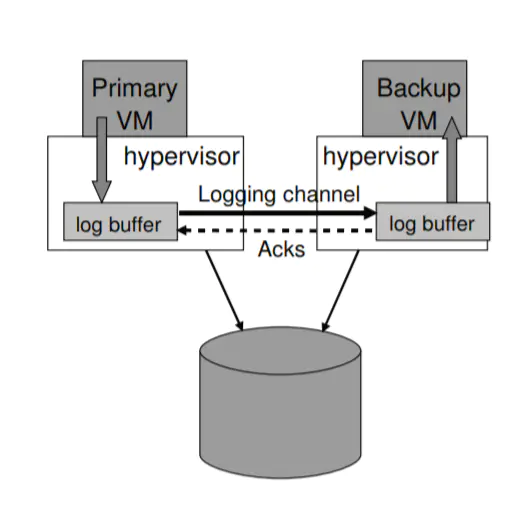
In our implementation, the hypervisors maintain a large buffer for logging entries for the primary and backup VMs. The backup sends acknowledgments back to the primary each time that it reads some log entries from the network into its log buffer. These acknowledgments allow VMware FT to determine when an output that is delayed by the Output Rule can be sent.
In our protocol for sending and acknowledging log entries, we send additional information to determine the real-time execution lag between the primary and backup VMs.
3.3 Operation on FT VMs #
Another practical matter is dealing with the various control operations (e.g. power off or increased CPU share) that may be applied to the primary VM. For these kind of operations, special control entries are sent on the logging, channel from the primary to the backup, in order to effect the appropriate operation on the backup.
The only operation that can be done independently on the primary and backup VMs is VMotion. That is, the primary and backup VMs can be VMotioned independently to other hosts.
VMotion of a primary VM or VMotion of a backup VM adds some complexity over a normal VMotion. For a normal VMotion, we require that all outstanding disk IOs be quiesced (i.e. completed) just as the final switchover on the VMotion occurs.
- For a primary VM, this quiescing is easily handled by waiting until the physical IOs complete and delivering these completions to the VM.
- For a backup VM, it requests via the logging channel that the primary VM temporarily quiesce all of its IOs.
3.4 Implementation Issues for Disk IOs #
There are a number of subtle implementation issues related to disk IO.
- Given that disk operations are non-blocking and so can execute in parallel, simultaneous disk operations that access the same disk location can lead to non-determinism. Our solution is generally to detect any such IO races (which are rare), and force such racing disk operations to execute sequentially in the same way on the primary and backup.
- A disk operation can also race with a memory access by an application (or OS) in a VM, because the disk operations directly access the memory of a VM via DMA. One solution is to set up page protection temporarily on pages that are targets of disk operations. Because changing MMU protections on page is an expensive operation, we choose instead to use bounce buffers. A bounce buffer is a temporary buffer that has the same size as the memory being accessed by a disk operation.
- There are some issues associated with disk IOs that are outstanding (i.e. not completed) on the primary when a failure happens, and the backup takes over. We re-issue the pending IOs during the go-live process of the backup VM. Because we have eliminated all races and all IOs specify directly which memory and disk blocks are accessed, these disk operations can be re-issued even if they have already completed successfully.
3.5 Implementation Issues for Network IO #
VMware vSphere provides many performance optimizations for VM networking. Some of these optimizations are based on the hypervisor asynchronously updating the state of the virtual machine’s network device.
The biggest change to the networking emulation code for FT is the disabling of the asynchronous network optimizations.
The elimination of the asynchronous updates of the network device combined with the delaying of sending packets described in Section 2.2 has provided some performance challenges for networking. We’ve taken two approaches to improving VM network performance while running FT.
- We implemented clustering optimizations to reduce VM traps and interrupts. When the VM is streaming data at a sufficient bit rate, the hypervisor can do on transmit trap per group of packets. Likewise, the hypervisor can reduce the number of interrupts to the VM for incoming packets by only posting the interrupt for a group of packets.
- Our second performance optimization for networking involves reducing the delay for transmitted packets. Our primary optimizations in this area involve ensuring that sending and receiving log entries and acknowledgments can call be done without any thread context switch. The VMware vSphere hypervisor allows functions to be registered with the TCP stack that will be called from a deferred-execution context (similar to a tasklet in Linux) whenever TCP data is received.
4. Design Alternatives #
4.1 Shared vs. Non-shared Disk #
In our default design, the primary and backup VMs share the same virtual disk. Therefore, the content of the shared disks is naturally correct and available if a failover occurs.
An alternative design is for the primary and backup VMs to have separate (non-shared) virtual disks. In this design, the backup VM does do all disk writes to its virtual disks.
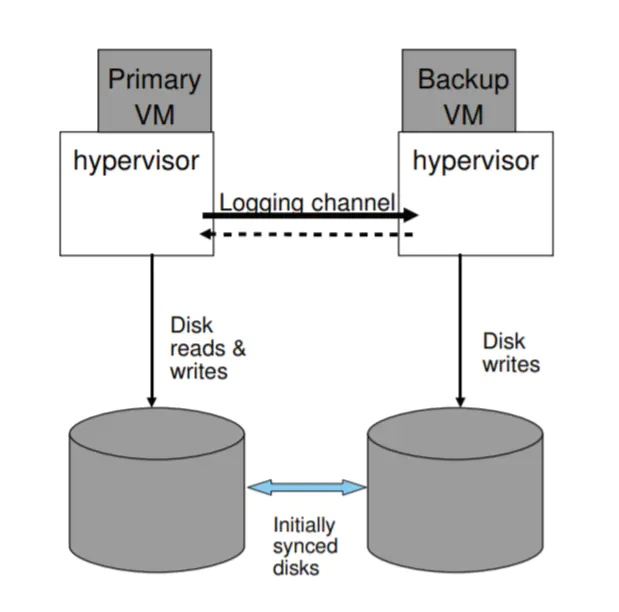
However, this approach has some disadvantages.
- The two copies of the virtual disks must be explicitly synced up in some manner when fault tolerance is first enabled.
- The disks can get out of sync after a failure, so they must be explicitly resynced when the backup VM is restarted after a failure. That is, FT VMotion must not only sync the running state of the primary and backup VMs, but also their disk state.
- There may no shared storage to use for dealing with a split-brain situation. In this case, the system could use some other external tiebreaker, such as a third-party server that both servers can talk to.
The non-shared design is quite useful in cases where shared storage is not accessible to the primary and backup VMs. This may be the case because shared storage is unavailable or too expensive, or because the servers running the primary and backup VMs are far apart (“long-distance FT”)
4.2 Executing Disk Reads on the Backup VM #
In our default design, the backup VM never reads from its virtual disk (whether shared or non-shared). Since the disk read is considered an input, it is natural to send the results of the disk read to the backup VM via the logging channel.
An alternative design is to have the backup VM execute disk reads and therefore eliminate the logging of disk read data. However, this approach has a number of subtleties.
- It may slow down the backup VM’s execution, since the backup VM must execute all disk reads and wait if they are not physically completed when it reaches the point in the VM execution where they completed on the primary.
- Some extra work must be done to deal with failed disk read operations.
- There is a subtlety if this disk-read alternative is used with the shared disk configuration. If the primary VM does a read to a particular disk location, then the disk write by a write to the same disk location, then the disk write must be delayed until the backup VM has executed the first disk read.
Executing disk reads on the backup VM may be useful in cases where the bandwidth of the logging channel is quite limited.
Related Resources #
- https://juejin.cn/post/6844903888848420872
- https://mr-dai.github.io/primary-backup-replication/
- https://www.cnblogs.com/brianleelxt/p/13245754.html
- http://blog.luoyuanhang.com/2017/05/20/ftvm-notes/
- https://riverferry.site/2021-02-12-The-Design-of-a-Practical-System-for-Fault-Tolerant-Virtual-Machines/