The Google File System #
Paper download: here
1. Introduction #
We have designed and implemented the Google File System (GFS) to meet the rapidly growing demands of Google’s data processing needs. GFS shares many of the same goals as previous distributed file systems such as performance, scalability, reliability and availability.
We have reexamined traditional choices and explored radically different points in the design space.
- Component failures are the norm rather than the exception.
- Files are huge by traditional standards.
- Most files are mutated by appending new data rather than overwriting existing data.
- Co-designing the applications and the file system API benefits the overall system by increasing our flexibility.
2. Design Overview #
2.1 Assumptions #
- The system is built from many inexpensive commodity components that often fail.
- The system stores a modest number of large files (>= 100MB)
- The workloads primarily consist of two kinds of reads: large streaming reads and small random reads.
- The workloads also have many large, sequential writes that append data to files. Once written, files are seldom modified again. Small writes at arbitrary positions in a file are supported but do not have to be efficient.
- The system must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file.
- High sustained bandwidth is more important than low latency.
2.2 Interface #
-
create / delete / open / close / read / write
-
snapshot / record append
2.3 Architecture #
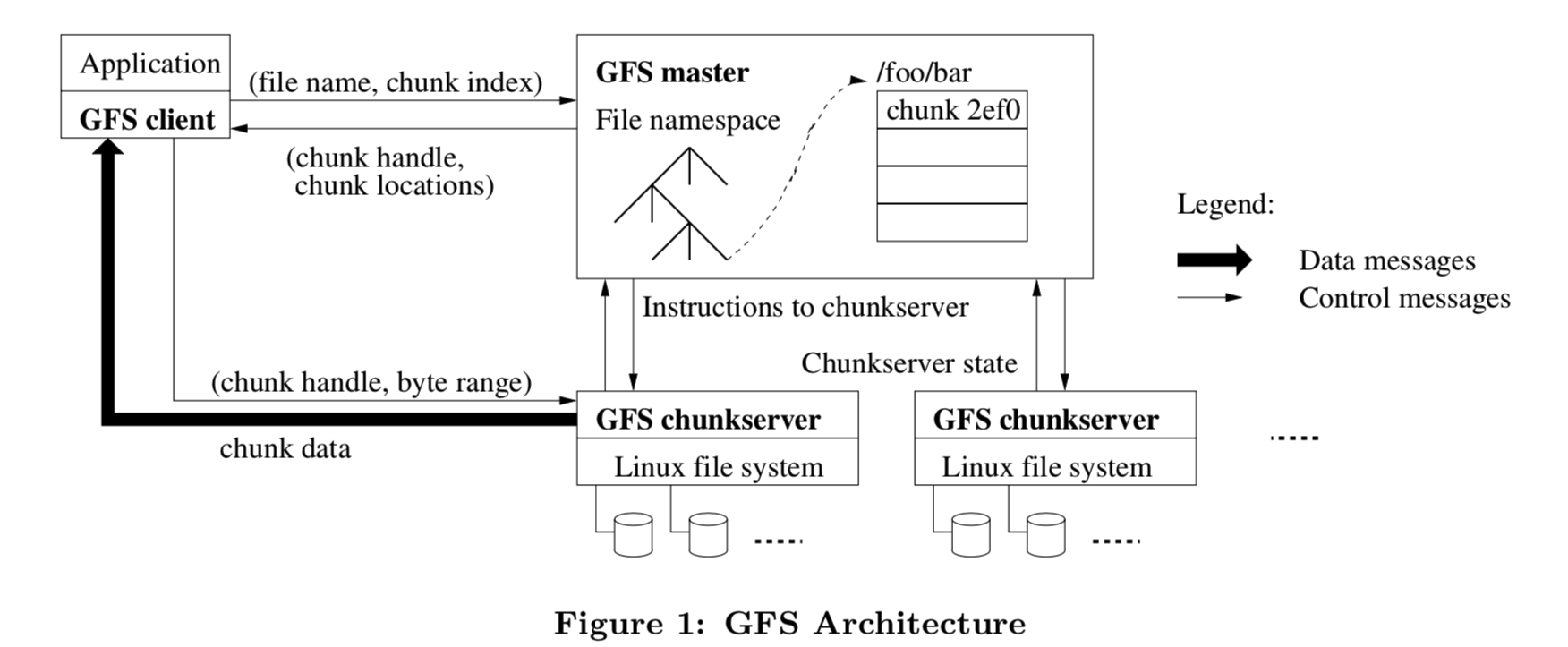
- Single master and multiple chunkservers.
- Files are divided into fixed-size chunks. Each chunk is identified by an unique 64 bit chunk handle assigned by the master. Each chunk has three replicas.
- The master maintains all file system metadata. This includes the namespace, access control information, the mapping from files to chunks, and the current location of chunks.
- Clients interact with the master for metadata operations, but all data-bearing communication goes directly to the chunkservers.
- Neither the client nor the chunkserver caches file data.
2.4 Single Master #
- Clients never read and write data through the master.
- A client asks the master which chunkservers it should contact. The client caches this information for a limited time and interacts with the chunkservers directly for many subsequent operations.
2.5 Chunk Size #
Chunk size is 64MB.
- It reduce clients' need to interact with the master.
- A client is more likely to perform many operations on a given chunk, it can reduce network overhead by keeping a persistent TCP connection to the chunkserver over an extended period of time.
- It reduces the size of the metadata stored on the master.
2.6 Metadata #
The master stores three major types of metadata: the file and chunk namespaces, the mapping of files to chunks, and the locations of each chunk’s replicas. All metadata is kept in the master’s memory. **The first two types (namespaces and file-to-chunk mapping) ** are also kept persistent by logging mutations to an operation log stored on the master’s local disk and replicated on remote machines.
The master does not store chunk location information persistently. Instead, it asks each chunkserver about its chunks at master startup and whenever a chunkserver joins the cluster.
2.6.1 In Memory Data Structures #
Advantages:
- The master will periodically scan the metadata’s state in the background.
- The periodic scanning is used to implement chunk garbage collection, re-replication in the presence of chunkserver failures, and chunk migration to balance load and disk space usage across chunkservers.
Disadvantages:
- The whole system is limited by how much memory the master has.
2.6.2 Chunk Locations #
The master does not keep a persistent record of which chunkservers have a replica of a given chunk.
The master controls all chunk placement and monitors chunkserver status with regular HeartBeat message
2.6.3 Operation Log #
The operation log contains a historical record of critical metadata changes. It is central of GFS.
We replicate operation log on multiple remote machines and respond to a client operation only after flushing the corresponding log record to disk both locally and remotely. The master batches several log records together before flushing thereby reducing the impact of flushing and replication on overall system throughput.
The master checkpoints its state whenever the log grows beyond a certain size so that it can recover by loading the latest checkpoint from local disk and replaying only the limited number of log records after that. The checkpoint is in a compact B-tree like from that can be directly mapped into memory and used for namespace lookup without extra parsing.
The master’s internal state is structured in such a way that a new checkpoint can be created without delaying incoming mutations. The master switches to a new log file and creates the new checkpoint in a separate thread.
2.7 Consistency Model #
2.7.1 Guarantees by GFS #
File namespace mutations (e.g., file creation) are atomic. They are handled exclusively by the master: namespace locking guarantees atomicity and correctness (Section 4.1); the master’s operation log defines a global total order of these operations (Section 2.6.3)
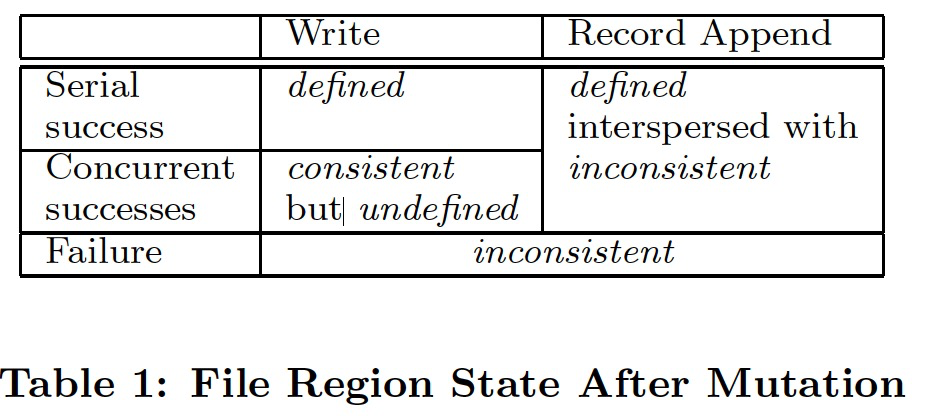
The states of a file region:
- consistent: all clients will always see the same data, regardless of which replicas they read from.
- defined: when a mutation succeeds without interference from concurrent writers; all clients will always see what the mutation has written
- undefined but consistent: concurrent successful mutations leave the region undefined but consistent; all clients see the same data, but it may not reflect what any one mutation has written.
- inconsistent: a failed mutation makes the region inconsistent (hence also undefined); different clients may see different data at different times.
How to distinguish defined regions from undefined region.
Data mutations may be writes or record appends. A write causes data to be written at an application-specified file offset. A record append causes data (the “record”) to be appended atomically at least once even in the presence of concurrent mutations, but at an offset of GFS’s choosing (Section 3.3). The offset is returned to the client and marks the beginning of a defined region that contains the record. In addition, GFS may insert padding or record duplicates in between. They occupy regions considered to be inconsistent and are typically dwarfed by the amount of user data.
The mutated file region is guaranteed to be defined and contain the data written by the last mutation. GFS achieves this by:
- applying mutations to a chunk in the same order on all its replicas (Section 3.1)
- using chunk version numbers to detect any replica that has become stale because it has missed mutations while its chunkserver was down (Section 4.5)
Since clients cache chunk locations, they may read from a stale replica before that information is refreshed. This window is limited by the cache entry’s timeout and the next open of the file, which purges from the cache all chunk information for that file.
Long after a successful mutation, component failures can of course still corrupt or destroy data. GFS identifies failed chunkservers by regular handshakes between master and all chunkservers and detects data corruption by checksumming (Section 5.2). Once a problem surfaces, the data is restored from valid replicas as soon as possible (Section 4.3)
2.7.2 Implications for Applications #
GFS applications can accommodate the relaxed consistency model with a few simple techniques already needed for other purposes: Relying on appends rather than overwrites, checkpointing, and writing self-validating, self-identifying records.
Practically all our applications mutate files by appending rather than overwriting. In one typical use, a writer generates a file from beginning to end. It atomically renames the file to a permanent name after writing all the data, or periodically checkpoints how much has been successfully written. Checkpointing allows writers to restart incrementally and keeps readers from processing successfully written file data that is still incomplete from the application’s perspective.
In the other typical use, many writers concurrently append to a file for merged results or as a producer-consumer queue. Record append’s append-at-least-once semantics preserves each writer’s output. Readers deal with the occasional padding and duplicates as follows. Each record prepared by the writer contains extra information like checksums so that its validity can be verified. A reader can identify and discard(丢弃) extra padding and record fragments using the checksums. If it cannot tolerate the occasional duplicates, it can filter them out using unique identifiers in the records.
3. System interactions #
We designed the system to minimize the master’s involvement in all operations.
3.1 Leases and Mutation Order #
A mutation is an operation that changes the contents or metadata of a chunk such as a write or an append operation. Each mutation is performed at all the chunk’s replicas. The global mutation order is defined first by the lease grant order chosen by the master, and within a lease by the serial numbers assigned by the primary.
The lease mechanism is designed to minimize management overhead at the master. A lease has an initial timeout of 60 seconds. As long as the chunk is being mutated, the primary can request and typically receive extensions from the master indefinitely. These extension requests and grants are piggybacked on the HeartBeat messages. Even if the master loses communication with a primary, it can safely grant a new lease to another replica after the old lease expires.
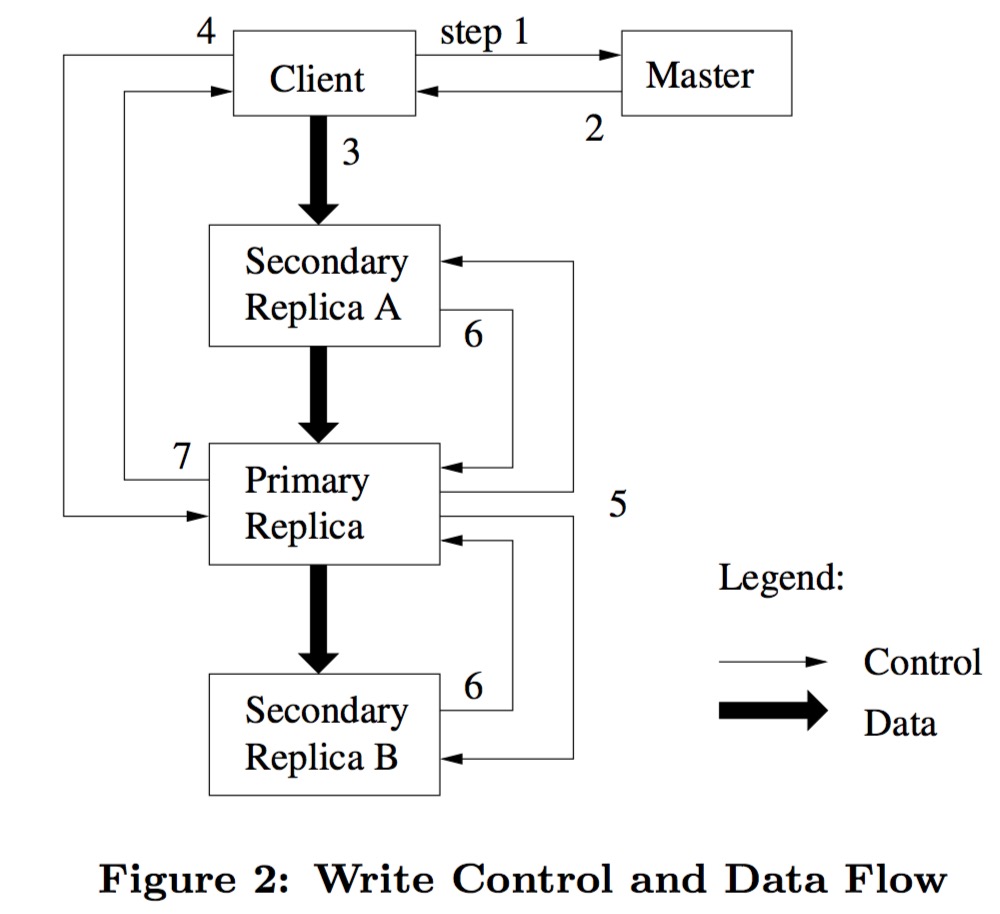
- The client asks the master which chunkserver holds the current lease for the chunk and the locations of the other replicas.
- The master replies with the identity of the primary and the locations of the other (secondary) replicas. The client caches this data for future mutations. It needs to contact the master again only when the primary becomes unreachable or replies that it no longer holds a lease.
- The client pushes the data to all replicas. Each chunkserver will store the data in an internal LRU buffer cache until the data is used or aged out.
- Once all the replicas have acknowledged receiving the data, the client sends a write request to the primary. The primary assigns consecutive(连续的) serial numbers to all the mutations it receives, possibly from multiple clients, which provides the necessary serialization. It applies the mutation to its own local state in serial number order.
- The primary forwards the write request to all secondary replicas. Each secondary replica applies mutations in the same serial number order assigned by the primary.
- The secondaries all reply to the primary indicating that they have completed the operation.
- The primary replies to the client. Any errors encountered at any of the replicas are reported to the client. Our client code handles such errors by retrying the failed mutation. It will make a few attempts at steps (3) through (7) before falling back to a retry from the beginning of the write.
If a write by the application is large or straddles a chunk boundary, GFS client code breaks it down into multiple write operations. They all follow the control flow described above but may be interleaved with and overwritten by concurrent operations from other clients. Therefore, the shared file region may end up containing fragments from different clients, although the replicas will be identical because the individual operations are completed successfully in the same order on all replicas. This leaves the file region in consistent but undefined as noted in Section 2.7
3.2 Data Flow #
We decouple the flow of data from the flow of control to use the network efficiently. While control flows from the client to the primary and then to all secondaries, data is pushed linearly along a carefully picked chain of chunkservers in a pipelined fashion. Our goals are to fully utilize each machine’s network bandwidth, avoid network bottlenecks and high-latency link, and minimize the latency to push through all the data.
To fully utilize each machine’s network bandwidth, the data is pushed linearly along a chain of chunkservers rather than distributed in some other topology (e.g., tree).
To avoid network bottlenecks and high-latency links (e.g., inter-switch links are often both) as much as possible, each machine forwards the data to the “closest” machine in the network topology that has not received it.
We minimize latency by pipelining the data transfer over TCP connections.
3.3 Atomic Record Appends #
GFS provides an atomic append operation called record append. In a traditional write, the client specifies the offset at which data is to be written. However, in a record append, the client specifies only the data.
Record append is heavily used by our distributed applications in which many clients on different machines append to the same file concurrently. In a traditional write, clients would need additional complicated and expensive synchronization, for example through a distributed lock manager. In our workloads, such files often serve as multiple-producer / single-consumer queues or contain merged results from many different clients.
Record append is a kind of mutation and follows the control flow in Section 3.1 with only a little extra logic at the primary. The clients pushes the data to all replicas of the last chunk of the file. Then, it sends its request to the primary. The primary checks to see if appending the record to the current chunk would cause the chunk to exceed the maximum size (64MB). If so, it pads the chunk to the maximum size, tells secondaries to do the same, and replies to the client indicating that the operation should be retried on the next chunk. (Record append is restricted to be at most one-fourth of the maximum chunk size to keep worst-case fragmentation at an acceptable level.) If the record fits within the maximum size, the primary appends the data to its replica, tells the secondaries to write the data at the exact offset where it has, and finally replies success to the client.
If a record append fails at any replica, the client retries the operation. As a result, replicas of the same chunk may contain different data possibly including duplicates of the same record in whole or in part. GFS does not guarantee that all replicas are bytewise identical. It only guarantees that the data is written at least once as an atomic unit. In terms of our consistency guarantees, the regions in which successful record append operations have written their data are defined (hence consistent), whereas intervening regions are inconsistent (hence undefined). Our applications can deal with inconsistent region as we discussed in Section 2.7.2
3.4 Snapshot #
The snapshot operation makes a copy of a file or a directory tree (the “source”) almost instantaneously, while minimizing any interruptions of ongoing mutations.
When the master receives a snapshot request, it first revokes any outstanding leases on the chunks in the files it is about to snapshot. This ensures that any subsequent writes to these chunks will require an interaction with the master to find the lease holder. This will give the master an opportunity to create a new copy of the chunk first.
After the lease have been revoked or have expired, the master logs the operation to disk. It then applies this log record to its in-memory state by duplicating the metadata for the source file or directory tree. The newly created snapshot files point to the same chunks as the source files.
The first time a client wants to write to a chunk C after the snapshot operation, it sends a request to the master to find the current lease holder. The master notices that the reference count for chunk C is greater than one. It defers replying to the client request and instead picks a new chunk handle C'. It then asks each chunkserver that has a current replica of C to create a new chunk called C'. By creating the new chunk on the same chunkservers as the original, we ensure that the data can be copied locally, not over the network. From this point, request handling is no different from that for any chunk: the master grants one of the replicas a lease on the new chunk C' and replies to the client, which can write the chunk normally, not knowing that it has just been created from an existing chunk.
4. Master Operation #
The master executes all namespace operations. In addition, it manages chunk replicas throughout the system: it makes placement decisions, creates new chunks and hence replicas, and coordinates various system-wide activities to keep chunks fully replicated, to balance load across all the chunkservers, and to reclaim unused storage.
4.1 Namespace Management and Locking #
We allow multiple operations to be active and use locks over regions of the namespace to ensure proper serialization.
GFS logically represents its namespace as a lookup table mapping full pathnames to metadata. With prefix compression, this table can be efficiently represented in memory. Each node in the namespace tree (either an absolute file name or absolute directory name) has an associated read-write lock.
Since the namespace can have many nodes, read-write lock objects are allocated lazily and deleted once they are not in use. Also locks are acquired in a consistent total order to prevent deadlock: they are first ordered by level in the namespace tree and lexicographically with in the same level.
4.2 Replica Placement #
The chunk replica placement policy serves two purposes:
- maximize data reliability and availability
- maximize network bandwidth utilization
4.3 Creation, Re-replication, Rebalancing #
The master considers several factors when it creates a chunk:
- We want to place new replicas on chunkservers with below-average disk space utilization.
- We want to limit the number of “recent” creations on each chunkserver.
- we want to spread replicas of a chunk across racks.
The master re-replicates a chunk as soon as the number of available replicas falls below a user-specified goal. This could happen for various reasons: a chunkserver becomes unavailable, it reports that its replica may be corrupted, one of its disks is disabled because of errors, or the replication goal is increased.
The master picks the highest priority chunk and “clones” it by instructing some chunkserver to copy the chunk data directly from an existing valid replica. The new replica is placed with goals similar to those for creation. To keep cloning traffic from overwhelming client traffic, the master limits the numbers of active clone operations both for the cluster and for each chunkserver. Additionally, each chunkserver limits the amount of bandwidth it spends on each clone operation by throttling its read requests to the source chunkserver.
The master rebalances replicas periodically: it examines the current replica distribution and moves replicas for better disk space and load balancing.
4.4 Garbage Collection #
After a file is deleted, GFS does not immediately reclaim the available physical storage. It does so only lazily during regular garbage collection at both the file and chunk levels.
4.4.1 Mechanism #
- Instead of reclaiming resources immediately, the file is just renamed to a hidden name that includes the deletion timestamp.
- During the master’s regular scan of the file system namespace, it removes any such hidden files if they have expired for more than three days (the interval is configurable)
- The file can still be read under the new, special name and can be undeleted by renaming it back to normal before deleting.
- In a similar regular scan of the chunk namespace, the master identifies orphaned chunks (i.e., those not reachable from any file) and erases the metadata for those chunks. In a HeartBeat Message regularly exchanged with the master, each chunkserver reports a subset of the chunks it has, and the master replies with the identity of all chunks that are no longer present in the master’s metadata. The chunkserver is free to delete its replicas of such chunks.
4.4.2 Discussion #
We can easily identify all references to chunks: they are in the file-to-chunk mappings maintained exclusively by the master.
We can easily identify all the chunk replicas: the are Linux files under designated directories on each chunkserver. Any such replica not known to the master is “garbage”.
The garbage collection approach to storage reclamation offers several advantages over eager deletion:
- It is simple and reliable in a large-scale distributed system where component failures are common. Garbage collection provides a uniform and dependable way to clean up any replicas not known to be useful.
- It merges storage reclamation into the regular background activities of the master, such as the regular scans of namespaces and handshakes with chunkservers.
- The delay in reclaiming storage provides a safety net against accidental, irreversible deletion.
Disadvantages:
- The delay sometimes hinders(阻碍) user effort to fine tune usage when storage is tight. We address these issues by expediting(促进,加快) storage reclamation if a deleted file is explicitly(明确地) deleted again. We also allow users to apply different replication and reclamation policies to different parts of the namespace.
4.5 Stale Replica Detection #
Chunk replicas may become stale if a chunkserver fails and misses mutations to the chunk while it is down. For each chunk, the master maintains a chunk version number to distinguish between up-to-date and stale replicas.
Whenever the master grants a new lease on a chunk, it increases the chunk version number and informs the up-to-date replicas.
The master includes the chunk version number when it informs clients which chunkserver holds a lease on a chunk or when it instructs a chunkserver to read the chunk from another chunkserver in a cloning operation.
5. Fault Tolerance and Diagnosis #
5.1 High Availability #
We keep the overall system highly available with two simple yet effective strategies: fast recovery and replication.
5.1.1 Fast Recovery #
Both the master and the chunkserver are designed to restore their state and start in seconds no matter how they terminated.
5.1.2 Chunk Replication #
Each chunk is replicated on multiple chunkservers on different racks. The default number of replicas is three. The master clones existing replicas as needed to keep each chunk fully replicated as chunkservers go offline or detect corrupted replicas through checksum verification.
5.1.3 Master Replication #
The master’s operation log and checkpoints are replicated on multiple machines. A mutation to the state is considered committed only after its log record has been flushed to disk locally and on all master replicas. For simplicity, one master process remains in charge of all mutations as well as background activities such as garbage collection that change the system internally. If its machine or disk fails, monitoring infrastructure outside GFS starts a new master process elsewhere with the replicated operation log.
Moreover, “shadow” masters which may lag the primary slightly provide read-only access to the file system even when the primary master is down. They enhance read availability for files that are not being actively mutated or applications that do not mind getting slightly stale results.
A shadow master reads a replica of the growing operation log and applies the same sequence of changes to its data structures exactly as the primary does. Like the primary, it polls chunkservers at startup (and infrequently thereafter) to locate chunk replicas and exchanges frequent handshake messages with them to monitor their status. It depends on the primary master only for replica location updates resulting from the primary’s decisions to create and delete replicas.
5.2 Data Integrity #
Each chunkserver uses checksumming to detect corruption of stored data. Each chunkserver must independently verify the integrity of its own copy ty maintaining checksums.
A chunk is broken up into 64KB blocks. Each has a corresponding 32 bit checksum. Like other metadata, checksums are kept in memory and stored persistently with logging, separate from user data.
For reads, the chunkserver verifies the checksum of data blocks that overlap the read range before returning any data to the requester, whether a client or another chunkserver. If a block does not match the recorded checksum, the chunkserver returns an error to the requestor and reports the mismatch to the master. In response, the requestor will read from other replicas, while the master will clone the chunk from another replica. After a valid new replica is in place, the master instructs the chunkserver that reported the mismatch to delete its replica.
Checksumming has little effect on read performance for several reasons. Since most of our reads span at least a few blocks, we need to read and checksum only a relatively small amount of extra data for verification. GFS client code further reduces this overhead by trying to align read at checksum block boundaries. Moreover, checksum lookups and comparison on the chunkserver are done without any I/O (checksum is stored in memory), and checksum calculation can often be overlapped with I/Os.
For append writes, we just incrementally update the checksum for the last partial checksum block, and compute new checksums for any brand new checksum blocks filled by the append.
For overwrites writes, we must read and verify the first and last blocks of the range being overwritten, then perform the write, and finally compute and record the new checksum.
During idle periods, chunkservers can scan and verify the contents of inactive chunks. Once the corruption is detected, the master can create a new uncorrupted replica and delete the corrupted replica.
5.3 Diagnostic Tools #
Extensive and detailed diagnostic logging has helped immeasurably in problem isolation, debugging, and performance analysis, while incurring only a minimal cost.
GFS servers generate diagnostic logs that record many significant events (such as chunkservers going up and down) and all RPC requests and replies. The RPC logs include the exact requests and responses sent on the wire, except for the file data being read or written.
The performance impact of logging is minimal (and far outweighed by the benefits) because these logs are written sequentially and asynchronously